Еще одна область исследований в области искусственного интеллекта — это нейронные сети. Они были разработаны по подобию естественных нейронных сетей нервной системы человека.
Искусственные нейронные сети
Изобретатель первого нейрокомпьютера, доктор Роберт Хехт-Нильсен, дал следующее понятие нейронной сети: «Нейронная сеть — это вычислительная система, состоящая из ряда простых, сильно взаимосвязанных элементов обработки, которые обрабатывают информацию путем их динамического реагирования на внешние воздействия».
Базовая структура искусственных нейронных сетей (ИНС)
Идея ИНС базируется на убеждении, что можно имитировать работу мозга человека, создав нужные связи с помощью кремния и проводов таких как у живых нейронов и дендритов.
Человеческий мозг состоит из 100 миллиардов нервных клеток, называемых нейронами. Они связаны с другими тысячами клеток Аксонами. Раздражители из внешней среды или сигналы от органов чувств принимаются дендритами. Эти входные сигналы создают электрические импульсы, которые быстро перемещаются через нейросеть. Затем нейрон может посылать сообщения на другие нейроны, которые могут отправить это сообщение дальше или могут вообще ее не отправлять.

Искусственные нейронные сети состоят из нескольких узлов, которые имитируют биологические нейроны человеческого мозга. Нейроны соединены между собой и взаимодействуют друг с другом. Узлы могут принимать входные данные и выполнять простейшие операции над данными. В результате этих операций данные передаются другим нейронам. Выходные данные для каждого узла называются его активацией.
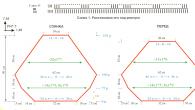
Каждое звено связано с весом. ИНС способны к обучению, которое осуществляется путем изменения значения веса. На следующем рисунке показана простая ИНС:
Типы искусственных нейронных сетей
Есть два типа искусственных нейронных сетевых топологий — с прямой связью и обратной связью.
Поток информации является однонаправленным. Блок передает информацию на другие единицы, от которых он не получает никакой информации. Нет петли обратной связи. Они имеют фиксированные входы и выходы.

Здесь, допускаются петли обратной связи.

Как работают искусственные нейронные сети
В топологии показаны схемы, каждая стрелка представляет собой связь между двумя нейронами и указывает путь для потока информации. Каждая связь имеет вес, целое число, которое контролирует сигнал между двумя нейронами.
Если сеть создает «хороший» и «нужный» выход, то нет необходимости корректировать вес. Однако если сеть создает «плохой» или «нежелательный» вывод или ошибку, то система корректирует свои весовые коэффициенты для улучшения последующих результатов.
Машинное обучение в искусственных нейронных сетях
ИНС способны к обучению, и они должны быть обучены. Существует несколько стратегий обучения
Обучение — включает в себя учителя, который подает в сеть обучающую выборку на которые учитель знает ответы. Сеть сравнивает свои результаты с ответами учителя и корректирует свои весовые коэффициенты.
Обучение без учителя — это необходимо, когда нет обучающей выборки с известными ответами. Например в задачах кластеризации, т.е. деления множества элементов на группы по каким-то критериям.
Обучение с подкреплением — эта стратегия, построенная на наблюдении. Сеть принимает решение наблюдая за своим окружением. Если наблюдение является отрицательным, сеть корректирует свои веса, чтобы иметь возможность делать разные необходимые решения.
Алгоритм обратного распространения
Байесовские сети (БС)
Эти графические структуры для представления вероятностных отношений между набором случайных переменных.
В этих сетях каждый узел представляет собой случайную переменную с конкретными предложениями. Например, в медицинской диагностике, узел Рак представляет собой предложение, что пациент имеет рак.
Ребра, соединяющие узлы представляют собой вероятностные зависимости между этими случайными величинами. Если из двух узлов, один влияет на другой узел, то они должны быть связаны напрямую. Сила связи между переменными количественно определяется вероятностью, которая связан с каждым узлом.
Есть только ограничение на дугах в БН, вы не можете вернуться обратно к узле просто следуя по направлению дуги. Отсюда БНС называют ациклическим графом.
Структура БН идеально подходит для объединения знаний и наблюдаемых данных. БН могут быть использованы, чтобы узнать причинно-следственные связи и понимать различные проблемы и предсказывать будущее, даже в случае отсутствия данных.
Где используются нейронные сети
Они способны выполнять задачи, которые просты для человека, но затруднительны для машин:
Аэрокосмические — автопилот самолета;
Автомобильные — автомобильные системы наведения;
Военные — сопровождение цели, автопилот, распознавание сигнала/изображения;
Электроника — прогнозирование, анализ неисправностей, машинное зрение, синтез голоса;
Финансовые — оценка недвижимости, кредитные консультанты, ипотека, портфель торговой компании и др.
Обработка сигнала — нейронные сети могут быть обучены для обработки звукового сигнала.
Искусственный интеллект создал нейросеть December 15th, 2017
Дожили до того момента, когда искусственный интеллект создаёт собственную нейросеть. Хотя многие думают, что это одно и тоже. Но на самом деле не всё так просто и сейчас мы попробуем разобраться что это такое и кто кого может создать.
Инженеры из подразделения Google Brain весной текущего года продемонстрировали AutoML. Этот искусственный интеллект умеет без участия человека производить собственные уникальнейшие ИИ. Как выяснилось совсем недавно, AutoML смог впервые создать NASNet, систему компьютерного зрения. Данная технология серьёзно превосходит все созданные ранее людьми аналоги. Эта основанная на искусственном интеллекте система может стать отличной помощницей в развитии, скажем, автономных автомобилей. Применима она и в робототехнике - роботы смогут выйти на абсолютно новый уровень.
Развитие AutoML проходит по уникальной обучающей системе с подкреплением. Речь идёт о нейросети-управленце, самостоятельно разрабатывающей абсолютно новые нейросети, предназначенные для тех или иных конкретных задач. В указанном нами случае AutoML имеет целью производство системы, максимально точно распознающей в реальном времени объекты в видеосюжете.
Искусственный интеллект сам смог обучить новую нейронную сеть, следя за ошибками и корректируя работу. Обучающий процесс повторялся многократно (тысячи раз), до тех пор, пока система не оказалась годной к работе. Любопытно, что она смогла обойти любые аналогичные нейросети, имеющиеся в настоящее время, но разработанные и обученные человеком.
При этом AutoML оценивает работу NASNеt и использует эту информацию для улучшения дочерней сети; этот процесс повторяется тысячи раз. Когда инженеры протестировали NASNet на наборах изображений ImageNet и COCO, она превзошла все существующие системы компьютерного зрения.
В Google официально заявили, что NASNet распознаёт с точностью равной 82,7%. Результат на 1.2 % превышает прошлый рекорд, который в начале осени нынешнего года установили исследователи из фирмы Momenta и специалисты Оксфорда. NASNet на 4% эффективнее своих аналогов со средней точностью в 43,1%.
Есть и упрощённый вариант NASNet, который адаптирован под мобильные платформы. Он превосходит аналоги чуть больше, чем на три процента. В скором будущем можно будет использовать данную систему для производства автономных автомобилей, для которых важно наличие компьютерного зрения. AutoML же продолжает производить новые потомственные нейросети, стремясь к покорению ещё больших высот.
При этом, конечно, возникают этические вопросы, связанные с опасениями по поводу ИИ: что, если AutoML будет создавать системы с такой скоростью, что общество просто за ними не поспеет? Впрочем, многие крупные компании стараются учитывать проблемы безопасности ИИ. Например, Amazon, Facebook, Apple и некоторые другие корпорации являются членами Партнерства по развитию ИИ (Partnership on AI to Benefit People and Society). Институт инженеров и электротехники (IEE) же предложил этические стандарты для ИИ, а DeepMind, например, анонсировал создание группы, которая будет заниматься моральными и этическими вопросами, связанными с применениями искусственного интеллекта.
Впрочем, многие крупные компании стараются учитывать проблемы безопасности ИИ. При этом, конечно, возникают этические вопросы, связанные с опасениями по поводу ИИ: что, если AutoML будет создавать системы с такой скоростью, что общество просто за ними не поспеет? Институт инженеров и электротехники (IEE) же предложил этические стандарты для ИИ, а DeepMind, например, анонсировал создание группы, которая будет заниматься моральными и этическими вопросами, связанными с применениями искусственного интеллекта. Например, Amazon, Facebook, Apple и некоторые другие корпорации являются членами Партнерства по развитию ИИ (Partnership on AI to Benefit People and Society).
Что такое искусственный интеллект?
Автором термина «искусственный интеллект» является Джон Маккарти, изобретатель языка Лисп, основоположник функционального программирования и лауреат премии Тьюринга за огромный вклад в области исследований искусственного интеллекта.
Искусственный интеллект — это способ сделать компьютер, компьютер-контролируемого робота или программу способную также разумно мыслить как человек.
Исследования в области ИИ осуществляются путем изучения умственных способностей человека, а затем полученные результаты этого исследования используются как основа для разработки интеллектуальных программ и систем.
Что такое нейронная сеть?
Идея нейросети заключается в том, чтобы собрать сложную структуру из очень простых элементов. Вряд ли можно считать разумным один-единственный участок мозга — а вот люди обычно на удивление неплохо проходят тест на IQ. Тем не менее до сих пор идею создания разума «из ничего» обычно высмеивали: шутке про тысячу обезьян с печатными машинками уже сотня лет, а при желании критику нейросетей можно найти даже у Цицерона, который ехидно предлагал до посинения подбрасывать в воздух жетоны с буквами, чтобы рано или поздно получился осмысленный текст. Однако в XXI веке оказалось, что классики ехидничали зря: именно армия обезьян с жетонами может при должном упорстве захватить мир.
На самом деле нейросеть можно собрать даже из спичечных коробков: это просто набор нехитрых правил, по которым обрабатывается информация. «Искусственным нейроном», или перцептроном, называется не какой-то особый прибор, а всего лишь несколько арифметических действий.
Работает перцептрон проще некуда: он получает несколько исходных чисел, умножает каждое на «ценность» этого числа (о ней чуть ниже), складывает и в зависимости от результата выдаёт 1 или -1. Например, мы фотографируем чистое поле и показываем нашему нейрону какую-нибудь точку на этой картинке — то есть посылаем ему в качестве двух сигналов случайные координаты. А затем спрашиваем: «Дорогой нейрон, здесь небо или земля?» — «Минус один, — отвечает болванчик, безмятежно разглядывая кучевое облако. — Ясно же, что земля».
«Тыкать пальцем в небо» — это и есть основное занятие перцептрона. Никакой точности от него ждать не приходится: с тем же успехом можно подбросить монетку. Магия начинается на следующей стадии, которая называется машинным обучением. Мы ведь знаем правильный ответ — а значит, можем записать его в свою программу. Вот и получается, что за каждую неверную догадку перцептрон в буквальном смысле получает штраф, а за верную — премию: «ценность» входящих сигналов вырастает или уменьшается. После этого программа прогоняется уже по новой формуле. Рано или поздно нейрон неизбежно «поймёт», что земля на фотографии снизу, а небо сверху, — то есть попросту начнёт игнорировать сигнал от того канала, по которому ему передают x-координаты. Если такому умудрённому опытом роботу подсунуть другую фотографию, то линию горизонта он, может, и не найдёт, но верх с низом уже точно не перепутает.
В реальной работе формулы немного сложнее, но принцип остаётся тем же. Перцептрон умеет выполнять только одну задачу: брать числа и раскладывать по двум стопкам. Самое интересное начинается тогда, когда таких элементов несколько, ведь входящие числа могут быть сигналами от других «кирпичиков»! Скажем, один нейрон будет пытаться отличить синие пиксели от зелёных, второй продолжит возиться с координатами, а третий попробует рассудить, у кого из этих двоих результаты ближе к истине. Если же натравить на синие пиксели сразу несколько нейронов и суммировать их результаты, то получится уже целый слой, в котором «лучшие ученики» будут получать дополнительные премии. Таким образом достаточно развесистая сеть может перелопатить целую гору данных и учесть при этом все свои ошибки.
Нейронную сеть можно сделать с помощью спичечных коробков — тогда у вас в арсенале появится фокус, которым можно развлекать гостей на вечеринках. Редакция МирФ уже попробовала — и смиренно признаёт превосходство искусственного интеллекта. Давайте научим неразумную материю играть в игру «11 палочек». Правила просты: на столе лежит 11 спичек, и в каждый ход можно взять либо одну, либо две. Побеждает тот, кто взял последнюю. Как же играть в это против «компьютера»?
Очень просто.
Берём 10 коробков или стаканчиков. На каждом пишем номер от 2 до 11.
Кладём в каждый коробок два камешка — чёрный и белый. Можно использовать любые предметы — лишь бы они отличались друг от друга. Всё — у нас есть сеть из десяти нейронов!
Нейросеть всегда ходит первой. Для начала посмотрите, сколько осталось спичек, и возьмите коробок с таким номером. На первом ходу это будет коробок №11. Возьмите из нужного коробка любой камешек. Можно закрыть глаза или кинуть монетку, главное — действовать наугад.
Если камень белый — нейросеть решает взять две спички. Если чёрный — одну. Положите камешек рядом с коробком, чтобы не забыть, какой именно «нейрон» принимал решение. После этого ходит человек — и так до тех пор, пока спички не закончатся.
Ну а теперь начинается самое интересное: обучение. Если сеть выиграла партию, то её надо наградить: кинуть в те «нейроны», которые участвовали в этой партии, по одному дополнительному камешку того же цвета, который выпал во время игры. Если же сеть проиграла — возьмите последний использованный коробок и выньте оттуда неудачно сыгравший камень. Может оказаться, что коробок уже пустой, — тогда «последним» считается предыдущий походивший нейрон. Во время следующей партии, попав на пустой коробок, нейросеть автоматически сдастся.
Вот и всё! Сыграйте так несколько партий. Сперва вы не заметите ничего подозрительного, но после каждого выигрыша сеть будет делать всё более и более удачные ходы — и где-то через десяток партий вы поймёте, что создали монстра, которого не в силах обыграть.
Источники:
Уже много лет человечество пытается научить компьютер думать самостоятельно, но пока количество ошибок слишком велико. Возможно ли преодолеть этот барьер
Попытки скопировать человеческий интеллект предпринимаются уже несколько веков. Еще в 1770 году венгерский изобретатель Вольфган фон Кемпелен создал автомат, который обыгрывал в шахматы всех, кто с ним состязался, и даже победил Наполеона Бонапарта. При этом для большего эффекта зрителям демонстрировались сложные механизмы машины. Позже изобретатель был разоблачен - внутри автомата сидел опытный шахматист, управляющий всем процессом. Однако событие успело наделать много шума.
Как все начиналось
Прошло много лет прежде чем в 50-е годы XX века Фрэнк Розенблатт изобрел персептрон - математическую модель связанных объектов, где входным сигналом для одного объекта служили выходные сигналы от других.
Самым главным свойством персептрона было так называемое обратное распространение ошибки. Это поле элементов (узлов), связанных друг с другом в сеть (матрица). Первоначально они одинаково реагируют на входящий сигнал - например оставляют его таким, как он был. Но допустим, мы хотим научить персептрон отличать буквы друг от друга. Мы подаем на вход то А, то Б, то Г в случайном порядке. Модель изначально не знает ничего ни про один из объектов, но ей дается обратная связь, по которой создается функция ошибки, определяющая, сильно ли ошиблась модель. В случае угадывания буквы функция выдает ноль (это значит, что ошибки нет). По мере того, насколько далек персептрон от правильного ответа, значение функции увеличивается. Сигнал об ошибке подается обратно на вход, что приводит к коррекции модели: у узлов в матрице менялись веса. В итоге персептрон запоминал свое состояние при определенных наборах входных объектов, то есть обучался.
Термин «обучение модели», к собственно обучению не имел никакого отношения. На самом деле, состояние модели приходило к равновесию после нескольких циклов обратного распространения ошибки. Также маятник приходит к равновесию после того, как его раскачали. Но сам факт, что модель могла запоминать свое состояние и оставаться в нем, похож на процесс обучения человека. Модель показалась ученым интересной и позже легла в основу первой нейронной сети.
Дальнейшее развитие теории нейросетей переживало многочисленные взлеты и падения на протяжении десятилетий. Среди наиболее известных открытий были первая модель искусственного интеллекта - Logic Theorist (LT, «логический теоретик»), изобретенная в 1956 году Алленом Ньюуэлом и Гербертом Саймоном, и «Элиза» - программа, поддерживающая разговор на английском языке на любую тему, созданная в 1965 году Джозефом Вайзенбаумом. Однако оказалось, что компьютерные возможности того времени не позволяли применять нейронные сети для более практических целей. В частности, для распознавания техники вероятного противника, на что так надеялись военные.
На 1990-е годы пришелся новый расцвет нейросетей. Достижения исследователей в области Data Mining (извлечения данных), машинного понимания и перевода языка, компьютерного зрения и других областях снова сделали актуальными изучение возможностей искусственного интеллекта. Развитие скорости процессоров и снижение стоимости памяти дали ученым возможность обучать нейросети быстрее и на более или менее реальных задачах. Но оказалось, что данных и ресурсов для обучения было мало, нейросети были «недостаточно разумны» - выдавали большой процент ошибок. Поэтому они нашли применение в специализированных задачах, например, распознавании символов, а общий интерес к искусственному интеллекту снова упал.
Нейроны человека и нейросети
Имеют ли нейросети какое-то отношение к нейронам в голове человека и можно ли называть их интеллектом?
Современное представление о процессе мышления человека основывается на том, что нейроны в коре головного мозга могут связываться друг с другом своими отростками-аксонами, периодически получая от «соседей» сигналы и переходя из базового в возбужденное состояние. В головном мозге человека насчитывается около 85-86 млрд нейронов, и один нейрон может иметь связи со многими (до 20 тысяч) другими нейронами. Тот факт, что эта структура способна мыслить, всегда привлекал внимание ученых.
Термин «искусственный интеллект» («artificial intelligence») был изобретен и впервые озвучен в 1956 году американским ученым Джоном Маккарти. В описание модели персептрона, о которой было рассказано выше, уже в 50-х – 60-х были введены статистические понятия узлов, сети и весов, и эти узлы под влиянием работ того времени по изучению человеческого мозга назвали нейронами.
В ходе развития искусственного интеллекта появилось множество типов сетей. В нашем мозге происходят одновременно и процессы распознавания образов, и текста, и картинок, и все это откладывается в памяти. Компьютерные же нейросети не столь универсальны: пришлось придумывать разные виды, каждый из которых лучше всего приспособлен для своей задачи: сверточные - в основном используются для анализа изображений, рекуррентные - для анализа динамических изменений, автокодировщики - для классификаций (например, для распознавания букв, символов), кодировщики-декодировщики - для выявления ключевых характеристик объекта, соревновательные нейросети - для порождения новых объектов, и специальные ячейки памяти (LTSM) - для запоминания и хранения информации.
Параллельно с типами нейросетей появилась и идея создания многослойных нейросетей, когда один слой одинаковых нейронов является входом для другого слоя. Позже также стали объединять разные типы слоев в одной модели, и все это с целью приблизить нейросети по уровню понимания к интеллекту человека.
Наши дни
Текущее внимание к нейросетям и активное использование термина «искусственный интеллект» обязано впечатляющим результатам, которых удалось добиться с переносом вычислений на видеокарты. Каждая из них содержит гораздо больше вычислительных ядер, чем центральный процессор, а также собственную память - это привело к ускорению обучения нейросетей в сотни раз по сравнению с обычными процессорами. Второй причиной нового витка в области AI стало возникновение огромных объемов данных для обучения.
Сейчас крупнейшие компании мира зарабатывают за счет нейросетей: соцсети (и их партнеры, как печально известная Cambridge Analitica) таргетируют рекламу при помощи аналитики, Nvidia и другие разработчики создают платформы для использования в автомобилях-автопилотах , способных качественно распознавать знаки и пешеходов на дорогах и реагировать на ситуацию. Однако ИИ применяют и в ближайшее время будут применять в основном для юридически не обязывающих действий. Они могут предупредить о появлении незнакомого лица на объекте или мошенника-рецидивиста в банке, упростят вождение, но не возьмут на себя ответственность за финальное решение.
Можно ли считать нейросети, служащие основой для решения задач классификации информации, искусственным интеллектом? Понять это можно, ответив на простой вопрос - может ли искусственный интеллект существовать и эффективно работать без естественного. Ответ - нет, потому что для решения любой задачи именно человек настраивает параметры нейросети для получения адекватных результатов. Грубо говоря, для решения каждой задачи выбирается своя архитектура нейросети. Ситуация, когда ИИ будет самостоятельно решать, какую нейросеть создать для решения конкретной задачи, пока даже не просматривается на горизонте.
Несмотря на то, что ИИ все-таки смог обыграть человека в шахматы, сейчас, как и несколько веков назад за каждой машиной, обыгрывающей человека, скрываются люди, создавшие ее.
Японский алгоритм написал книгу “День, когда Компьютер написал роман”. Несмотря на то что с характерами героев и сюжетными линиями неопытному писателю помогали люди, компьютер проделал огромную работу – в итоге одна из его работ прошла отборочный этап престижной литературной премии. Нейросети также написали продолжения к Гарри Поттеру и Игре Престолов .
В 2015 году нейросеть AlphaGo, разработанная командой Google DeepMind, стала первой программой, победившей профессионального игрока в го . А в мае этого года программа обыграла сильнейшего игрока в го в мире , Кэ Цзэ. Это стало прорывом, поскольку долгое время считалось, что компьютеры не обладают интуицией, необходимой для игры в го.
Безопасность
Команда разработчиков из Технологического университета Сиднея представила дронов для патрулирования пляжей. Основной задачей дронов станет поиск акул в прибрежных водах и предупреждение людей на пляжах . Анализ видеоданных производят нейросети, что существенно отразилось на результатах: разработчики утверждают о вероятности обнаружения и идентификации акул до 90%, тогда как оператор, просматривающий видео с беспилотников, успешно распознает акул лишь в 20-30% случаев.Австралия занимает второе место в мире после США по количеству случаев нападения акул на людей. В 2016 году в этой стране были зафиксированы 26 случаев нападения акул, два из которых закончились смертью людей.
В 2014 году Лаборатория Касперского сообщала, что их антивирус регистрирует 325 тыс. новых зараженных файлов ежедневно. В то же время, исследование компании Deep Instinct показало, что новые версии вирусов практически не отличаются от предыдущих – изменение составляет от 2% до 10%. Самообучающаяся модель, разработанная Deep Instinct, на основании этой информации способна с высокой точностью определять зараженные файлы .
Нейросети также способны искать определенные закономерности в том, как хранится информация в облачных сервисах, и сообщать об обнаруженных аномалиях, способных привести к бреши в безопасности.
Бонус: нейросети на страже нашего газона
В 2016 году 65-летний инженер NVIDIA Роберт Бонд столкнулся с проблемой: соседские кошки регулярно посещали его участок и оставляли следы своего присутствия, что раздражало его жену, работающую в саду. Бонд сразу отсек слишком недружелюбную идею соорудить ловушки для незваных гостей. Вместо этого он решил написать алгоритм, который бы автоматически включал садовые разбрызгиватели воды при приближении кошек.Перед Робертом стояла задача идентификации кошек в поступающем с внешней камеры видеопотоке. Для этого он использовал систему, основанную на популярной нейросети Caffe. Каждый раз, когда камера наблюдала изменение в обстановке на участке, она делала семь снимков и передавала их нейросети. После этого нейросеть должна была определить, присутствует ли в кадре кошка, и, в случае утвердительного ответа, включить разбрызгиватели.

Изображение с камеры во дворе Бонда
До начала работы нейросеть прошла обучение: Бонд “скормил” ей 300 разных фотографий кошек. Анализируя эти фотографии, нейросеть училась распознавать животных. Но этого оказалось недостаточно: она корректно определяла кошек лишь в 30% случаев и приняла за кошку тень Бонда, в результате чего он сам оказался мокрым.
Нейросеть заработала лучше после дополнительного обучения на большем количестве фотографий. Однако Бонд предупреждает, что нейросеть можно натренировать слишком сильно, в случае чего у нее сложится нереалистичный стереотип – например, если все снимки, использующиеся для обучения, сняты с одного ракурса, то искусственный интеллект может не распознать ту же самую кошку с другого угла. Поэтому чрезвычайно важным является грамотный подбор обучающего ряда данных.
Через некоторое время кошки, обучившиеся не на фотографиях, но на собственной шкуре, перестали посещать участок Бонда.
Заключение
Нейронные сети, технология середины прошлого века, сейчас меняет работу целых отраслей. Реакция общества неоднозначна: одних возможности нейросетей приводят в восторг, а других – заставляют усомниться в их пользе как специалистов.Однако не везде, куда приходит машинное обучение, оно вытесняет людей. Если нейросеть ставит диагнозы лучше живого врача, это не значит, что в будущем нас будут лечить исключительно роботы. Вероятнее, врач будет работать вместе с нейросетью. Аналогично, суперкомпьютер IBM Deep Blue выиграл в шахматы у Гарри Каспарова еще в 1997 году, однако люди из шахмат никуда не делись, а именитые гроссмейстеры до сих пор попадают на обложки глянцевых журналов.
Кооперация с машинами принесет гораздо больше пользы, чем конфронтация. Поэтому мы собрали список материалов в открытом доступе, которые помогут вам продолжить знакомство с нейросетями:
19 декабря в рамках лекционного проекта Фонда Егора Гайдара состоялось выступление кандидата физико-математических наук, руководителя проекта iPavlov и заведующего лабораторией нейронных систем и глубокого обучения Московского физико-технического института (МФТИ) Михаила Бурцева, в рамках которого он рассказал о перспективах построения искусственного интеллекта, работающего по образцу человеческого мозга. Модератором мероприятия выступил экономический обозреватель Борис Грозовский. Подробности лекции эксперта - в видео “Ъ” и стенограмме доклада.
Фонд Егора Гайдара при информационной поддержке “Ъ” запустил курс лекционного проекта «Экономический факультет» «Экономика наступившего будущего». В курс вошли четыре лекции, посвященные высоким технологиям,- криптовалютам, блокчейну, искусственному интеллекту и нейронным сетям, большим данным.
Первая лекция цикла «Экономика наступившего будущего», посвященная криптовалютам, состоялась 21 ноября. Подробнее - в материале “Ъ” «Криптовалюты: новая экономика или новая пирамида?» .
Вторая лекция состоялась 5 декабря и была посвящена перспективам внедрения искусственного интеллекта. Подробнее - в материале “Ъ” «Человек и машина - выгодный союз или жесткая конкуренция?» .
Стенограмма лекции
Когда меня пригласили прочитать лекцию, мне очень понравилось название цикла - «Экономика наступившего будущего». Я занимаюсь нейросетями больше десяти лет, но последние два-три года часто возникает ощущение, что будущее неотвратимо наступает. В этом плане название цикла как нельзя лучше отражает то, о чем я хотел бы рассказать и что мы могли бы пообсуждать после лекции. Соответственно, я планирую рассказать вам о том, что собой представляют нейронные сети и как они используются сегодня для создания интеллектуальных систем. Было также заявлено «как они изменят нашу жизнь», но об этом мы как раз сможем поговорить в более интерактивной форме, потому что тут, я думаю, вопрос открытый. Мне самому интересно, какие вы видите возможности, которых не вижу я.
Давайте начнем с того, что же такое искусственный интеллект. Попробуем определить предмет, про который мы говорим. Классическое определение искусственного интеллекта - это построение некоторых машин, которые будут обладать интеллектом, сопоставимым с интеллектом человека. Но возникает вопрос: зачем мы этим занимаемся? Зачем общество этим занимается? Здесь, мне кажется, есть две грани. Первая грань - это прикладная цель, которая в первую очередь приходит в голову, когда мы слышим об искусственном интеллекте. Мы хотим получить помощника, который, скажем так, дополнит наш естественный интеллект, позволив нам решать какие-то задачи. Как калькулятор сильно упростил нам жизнь, позволив сделать то, что еще сто лет назад считалось сильно интеллектуальным,- умножение, сложение, деление больших чисел. Это предок искусственного интеллекта. Вторая грань - если мы посмотрим на искусственный интеллект как на фундаментальную программу исследования, то на самом деле, так как мы хотим построить машину, сопоставимую по интеллекту с человеком, то мы неизбежно задаемся вопросом: что же представляет собой интеллект человека? Как говорил Ричард Фейнман: «Чтобы что-то понять, мне нужно знать, как это построить». Так и здесь. Строя искусственный интеллект, мы в каком-то смысле лучше разбираемся, как устроен естественный интеллект. И в этом смысле мы проникаем в область философии, то есть мы разбираемся с природой человека. Как устроен человек, какие у него мотивы, почему он ведет себя тем или иным образом. То есть это очень интересно именно с исследовательской точки зрения. Это, как мне кажется, основные причины, почему мы занимаемся искусственным интеллектом.
Давайте вкратце рассмотрим, как вообще мы можем строить искусственный интеллект. Представьте, что вы стали организатором проекта по созданию искусственного интеллекта. С чего вы начнете? Какие есть варианты? Первое - взломать голову. Мы исследуем, как состоящий из нейронов мозг решает какую-то задачу, и потом, понимая принципы, как эти составные части взаимодействуют, строим работающий алгоритм. То есть мы будем строить модель мозга из нейронов, и, соответственно, у нас получится искусственная нейронная сеть. Второй путь - разобраться, что такое интеллект. Мы можем взять людей, которые решают интеллектуальные задачи, и сверить процесс. Как они это делают, какие приемы используют, в какой момент у них возникает, например, доказательство математической теоремы. Потом мы попытаемся построить некую модель решения интеллектуальных задач, формализуем ее и будем пытаться запустить на компьютере, чтобы она порождала такие же интеллектуальные результаты. Это два основных подхода к тому, как вообще люди делают искусственный интеллект: один основан на моделировании биологической системы мозга, а второй - на рассуждении человека. Это то, что называется «символьный искусственный интеллект», а до недавнего времени называлось «традиционный искусственный интеллект» или «искусственный интеллект», но сегодня происходит переход с понятия «символьного искусственного интеллекта» на понятие «нейросетевой».
Вкратце история - как вообще появилось такое направление исследований, как искусственный интеллект. В середине прошлого века Норберт Винер придумал науку, которая называлась кибернетикой. Это наука, которая попыталась формализовать и построить модель организации, при этом отделив саму модель организации от субстрата, на которой эта организация может разворачиваться. То есть это может быть организация клеток в организме, может быть организация людей в обществе или организация каких-то механических артефактов, которые образует искусственный интеллект. Соответственно, зарождение искусственного интеллекта началось с кибернетики, с построения робототехнических машин, которые могли решать какие-то задачи. Они могли ехать на свет или, наоборот, прятаться от света, объезжать препятствия. Когда появились компьютеры, это открыло возможность для появления искусственного интеллекта именно в том виде, в котором мы его наблюдаем сегодня - как некоторой программы, которая управляет компьютером и может, например, давать осмысленные ответы. Бурная попытка применить алгоритм искусственного интеллекта к решению практических задач показала, что какие-то простые задачи мы можем решить достаточно быстро даже на тех примитивных компьютерах, которые появились в середине 1950-х - начале 1960-х годов. Одно из известных достижений того времени - программа «Логик-теоретик», которая на основании аксиомы смогла доказать все теоремы школьной геометрии.
У людей были очень высокие ожидания. Можно сказать, что был такой хайп искусственного интеллекта. Военные и правительства вкладывали кучу денег, и это вылилось в то, что мы называем «золотые годы искусственного интеллекта». Параллельно в тени развивался наш нейросетевой искусственный интеллект. При этом если мы почитаем, какие прогнозы давали ведущие исследователи в то время, то увидим, что в 1960-е годы они говорили, что через десять лет компьютер сможет выполнять работу среднестатистического человека. Такие заявления делались на регулярной основе всеми, и понятно, почему им давалось так много денег. Кто откажется от того, чтобы у него был робот, который через десять лет будет делать все, что делает человек? В связи с этим так же понятно, почему исследования искусственного интеллекта были заморожены. Когда те люди, которые давали деньги, через десять лет не увидели того, что им обещали, они решили, что все это пустое, и прикрыли финансирование.
Несмотря на это было наработано достаточно большое количество алгоритмов и подходов к решению задач. И они оказались применимы в некоторых узких областях. Оказалось, что можно построить экспертные системы на основании некоторых входных данных и описывающих ее состояние фактов и, например, диагностировать какие-то заболевания. В результате к искусственному интеллекту на некоторое время вернулись, но при этом сами системы не получили широкого распространения. То есть удалось закрыть несколько предметных областей, а дальше развитие уперлось в потолок. Одновременно возродился интерес к искусственным нейронным сетям, возникли всякие модели параллельных распределенных вычислений и так далее. И здесь удалось получить различные результаты по кластеризации и нейросетевой памяти. Но эти исследования так и остались в основном в рамках исследовательских лабораторий.
Начиная с конца 1990-х годов и до последнего времени в течение двадцати лет, мы наблюдали такую вялотекущую ситуацию, когда слово «искусственный интеллект» вышло из употребления нормальными учеными. Считалось, что если кто-то говорит, что он занимается искусственным интеллектом, это, наверное, не профессиональный ученый, а такой увлекающийся мыслитель-любитель, который пытается что-то сочинить. То есть человек не мог признаться, даже если он занимался искусственным интеллектом, что он занимается искусственным интеллектом. Поэтому это стали называть машинным обучением. Что значит машинное обучение? Это такой прагматический подход. Допустим, у нас есть набор методов - математическая статистика, методы оптимизации и так далее. Мы будем их использовать для решения практических задач и все это назовем машинным обучением. При этом удалось решить много интересных прикладных задач, и так продолжалось до 2012 года. А в 2012 году появился замечательный термин - «глубокое обучение».
Оказалось, что начиная с середины 2000-х годов нейросети снова стали набирать эффективность и показывать в лабораториях хорошие результаты. Есть задача категоризации изображений, когда имеется несколько миллионов изображений и тысяча категорий, и вам нужно по изображению определить, к какой категории оно относится. Соответственно, в 2010 году самый лучший алгоритм такой классификации давал ошибку около 27%. Но между 2010 и 2012 годом произошло очень сильное падение этой ошибки. То есть алгоритмы стали качественно лучше решать эту задачу. И если человек неправильно классифицирует изображения в конкретном наборе в 5% случаев, то алгоритм тогда делал 4,5% ошибок, а сейчас - уже 3%. Такой быстрый прогресс в данной области был связан с тем, что как раз здесь были впервые применены нейросетевые методы. А затем уже каждое решение, которое улучшало результат предыдущего года, было основано на нейросетях. Почему они называются глубокими, мы узнаем позже.
Так что же такое искусственные нейронные сети? Давайте попробуем разобраться. Начнем с того, что посмотрим, как устроены естественные нейронные сети. Обычно для этого изучается мозг лабораторных мышей С57black6 - такая линейка черных мышей. Одна из областей мозга называется гиппокамп. Чем она интересна? Тем, что это область, от которой очень сильно зависит эпизодическая память. В гиппокампе есть подобласть, которая называется «зубчатая фасция». Она позволяет распознавать очень близко лежащие друг к другу контексты, и, что самое интересное, в этой области происходит нейрогенез. То есть там на протяжении всей жизни у взрослого животного рождаются нейроны. Утверждение, что нейроны не восстанавливаются, на самом деле ошибочно - в мозге человека и других животных нейроны делятся и растут.
Что собой представляют отдельные нейроны гранулярного слоя зубчатой фасции? Нейрон состоит из трех частей: продолговатое тело клетки, дендритное дерево, которое принимает сигналы от других клеток, и тонкий отросток, так называемый аксон, который позволяет передавать информацию другим клеткам. Как это происходит? На дендритном дереве есть отростки, которые называются шипиками. На концах этих шипиков - синапсы. Из аксонов выбрасывается некоторое химическое вещество, которое называется нейромедиатором. Везикулы, которые наполнены нейромедиаторами, соединяются с мембраной и выбрасываются в межклеточное пространство. Чтобы почувствовать этот сигнал, нам нужно, чтобы другая клетка получила эти химические молекулы и каким-то образом почувствовала их. Для этого между клетками устанавливается так называемый синапс - такое уплотнение, в котором молекулы, специальные клеточные адгезии, связывают мембраны двух клеток. Также сюда вставляются рецепторы - это молекулы, которые позволяют определить, что присутствуют какие-то химические вещества. Таким образом, в синаптическую щель между двумя мембранами выбрасывается некоторое химическое вещество, молекулы, которые находятся на мембране постсинаптического нейрона, чувствуют это вещество, и сигнал передается внутрь клетки. Сигналы с разных частей нашего дендритного дерева собираются на теле, и клетка может, например, в какой-то момент решить, что она должна послать сигнал другим клеткам, которые находятся в мозге.
Теперь представьте, что в вашем мозге 80 млрд клеток шлют друг другу химические сигналы, и вы ощущаете, например, удовольствие от того, что придумали стихотворение, или вы наслаждаетесь какой-то прекрасной мелодией, или вы влюбились в кого-то. Все это определяется взаимодействием между этими клетками. А когда вы изучаете что-то новое, ваша память об этом новом и то знание, которое вы приобретаете, сохраняется в контактах. То есть клетки усиливают контакты друг с другом, как-то их модифицируют, и за счет этого мы можем обучаться, что-то помнить, чувствовать и управлять нашим поведением.
Теперь давайте попробуем смоделировать наш мозг. Как будет выглядеть простейшая, самая примитивная модель нервной клетки. Сверху у нас есть дендритное дерево, там же входы некоторого нашего алгоритма. На вход подаются значения Х1, Х2 Х3, Х4 и Х5. Число пропорционально тому объему нейромедиатора, который на нас выбросила другая клетка. Понятно, что какие-то клетки в момент времени могут этого вещества выбросить больше, какие-то - меньше. Соответственно, каждый раз эти Х1, Х2 Х3, Х4 и Х5 могут быть разными. Но чтобы почувствовать эти молекулы, нам нужен рецептор с другой стороны. Потому что если рецепторов ноль, то сколько бы на нас ни выбрасывали этого химического вещества, наша клетка ничего не почувствует. Чтобы смоделировать нашу чувствительность к этому веществу, мы ее описываем при помощи некоторого коэффициента W. Это называется - вес связи. Соответственно, если значение большое и вес большой, то мы их перемножаем и получаем большое влияние данного входа на нашу активность. Если же химический сигнал, который нам послали, нулевой, несмотря на то, что в другом месте может быть хороший синапс, то этот вход никак не повлияет на нашу активность. С другой стороны, при одинаковом объеме нейромедиатора тот вход, который имеет больший вес, сильнее повлияет на активность нашего нейрона.
То есть что мы делаем? Мы считаем, насколько каждый вход повлиял на нашу активность - просто берем, суммируем, перемножаем каждое значение на вес и подсчитываем их сумму. Затем мы должны определить Y. Обычно в машинном обучении то, что у нас поступает на вход нашей программы, называется Х, а то, что мы получаем на выходе - Y. Чтобы посчитать наш Y, делаем некоторое преобразование и рассчитываем функцию от суммы воздействия для того, чтобы смоделировать пороговое действие нейрона. То есть пока у нас порог воздействия не преодолен, наш нейрон не активен. Когда эта суммарная активность превышает порог, то в зависимости от функции - она называется функцией активации - мы можем регулировать порог, например, смещением, которое обычно называется W. При этом мы можем посчитать, какой выход будет у нашего нейрона. Обычно если у нас порог, про который я говорил, превышен, то значение Y будет большим, ну или стремиться к единице, а если маленьким, то будет либо минус единица, либо ноль, либо уходить в минус бесконечность, в зависимости от того, какую активационную функцию мы выберем.
Хорошо, мы поняли, что представляет собой отдельный нейрон. Но мозг состоит не из одного нейрона - у нас 80 миллиардов, а у мыши несколько сот миллионов. Теперь мы должны объединить эти нейроны в сеть. Что у нас происходит? Когда мы погружены в окружающий мир, то если мы посмотрим на зрительную систему, то у нас есть палочки, колбочки, фотоактивируемые клетки, которые в зависимости от того, сколько на них попало света, моделируют свою активность. Естественно, затем эти сигналы передаются по цепочке все глубже в мозг, и мозг пытается восстановить картину мира, который нас окружает. Соответственно, у нас есть входной слой нашей сети и есть некоторый скрытый слой. То есть вы идете по улице, переходите улицу, обернулись и вдруг увидели, что на вас мчится машина. У вас сигнал поступил, перешел в скрытый слой, ваша модель мира сработала и предсказала, что машина может в вас врезаться, если вы не ускорите шаг или не отскочите назад. И есть выходные элементы. Это мотонейроны, которые управляют вашим движением. Они приводят к изменению поведения - вы не идете спокойно, а пытаетесь отскочить в сторону или как-то грозите кулаком водителю, то есть предпринимаете какие-то действия. Таким образом, мы строим из наших нейронов многослойную нейронную сеть. Чем больше у нее слоев, тем она глубже. Поэтому глубокие сети - это те сети, в которых больше пяти, может быть, сотни слоев и очень много нейронов. Так мы принимаем решения.
Давайте немного упростим задачу, скажем, на примере классификации изображений. Как мы ее рассматриваем? У нас есть изображение. Что мы будем подавать на вход нашей нейросети? Мы будем подавать описание пикселей. То есть если у нас есть изображение 10х10, то там 100 пикселей. Предположим, у нас есть красный, зеленый и синий - соответственно, у нас есть 300 значений: Х1, Х2 - и до Х300. Предположим, мы решаем задачу: у нас есть много изображений, и нам для нашего бизнеса необходимо отличать кошек от Незнайки. Кошку мы пропускаем, а Незнайку не пропускаем. Потому что кошка должна ловить в подвале мышей, а Незнайка может сломать водопровод. Мы строим систему видеонаблюдения, где на вход подаем изображение, и есть два выхода - система должна выдать 1, если Незнайка, и 0, если кошка.
Чем задается правильность функционирования сети? Функция активации обычно фиксирована, соответственно, у нас есть пороги и W - вот эти веса. Вначале, когда у нас есть фотографии, мы не знаем, какие веса соответствуют в этой сети правильному решению. Нам нужно подобрать эти веса таким образом, чтобы ошибка по отличению Незнайки от кошки была минимальной. Здесь мы видим, чем нейросеть отличается от стандартного программирования. Потому что если программирование стандартное, мы подойдем к этой задаче как ИТ-программист: «Ага, я должен придумать, по каким признакам кошка отличается от Незнайки. Потом я напишу программу, которая в изображениях будет искать эти признаки кошки или Незнайки и при помощи условий - вот это кошка, вот это Незнайка - вычислять эту функцию». Мы же говорим, что мы не хотим знать, чем кошка отличается от Незнайки, нам плевать. Мы сделаем специальный алгоритм обучения, который сам построит такую функцию, которая будет решать нашу задачу. То есть мы не пишем программу руками, а мы как бы обучаем программу получать тот функционал, который нам необходим.
Как мы это будем делать? У нас есть некоторый набор примеров, это называется обучающая выборка, чем больше примеров, тем лучше. Например, у нас есть 10 тыс. изображений Незнайки и 10 тыс. изображений кошки, которых мы уже сфотографировали и для которых мы уже заранее знаем, где кошка, а где Незнайка. Теперь мы хотим на основе этих изображений подобрать веса таким образом, чтобы, когда у нас появятся новые изображения кошки и Незнайки, которых мы никогда не видели, система все равно могла их различить. Мы это делаем так. Сначала мы эти веса задаем случайным образом и начинаем подавать на вход изображения. Как вы думает, что будет на выходе, если мы зададим веса случайным образом? Можно назвать это бардаком. Система будет случайно называть ответ. И тут мы переходим к самой интересной части нейронных сетей - к так называемому алгоритму обратного распространения ошибки.
Как мы можем изменять веса? Мы их можем изменять следующим образом. Мы подали картинку, рассчитали все активности всех нейронов сначала в одном слое, потом в другом, и так во всех промежуточных слоях, пока не дойдем до выхода. На выходе мы имеем некоторый ответ, где Незнайка, а где кошка. Мы сравниваем тот ответ, который дала нейронная сеть, с тем ответом, который является у нас истинным. Потому что мы уже знаем все ответы для всех картинок в обучающей выборке. И рассчитываем ошибку. Если, например, у нас на выходе было 0,5, а нужно, чтобы была единица, следовательно, у нас ошибка минус 0,5. То есть мы как бы говорим о том, что нам не хватает минус 0,5 для того, чтобы дать правильный ответ по данному выходу. Или, наоборот, если у нас был слишком маленький выход, а мы его хотим увеличить, то у нас будет положительная ошибка. Затем нам нужно как-то учесть вклад весов в эту ошибку. Теперь нам надо узнать, как эти два нейрона и два веса повлияли на вклад в ошибку. Какие допущения мы можем сделать, чтобы посчитать разницу, насколько нам нужно каждый из весов изменить? На самом деле, мы видим, во-первых, активность этих нейронов, во-вторых, вес, и можем посчитать, какой из нейронов какой вклад в эту ошибку внес. Например, если этот нейрон не был активен, он был равен нулю, то он никакого вклада в эту ошибку не внес. С другой стороны, чем более активен нейрон, тем больший вклад он внес. Но если они были одинаково активны, то больший вклад в ошибку внес тот, у кого вес больше. Соответственно, изменение веса должно быть пропорционально ему самому, плюс пропорционально активности нейрона с предыдущего слоя и пропорционально производной нашей функции активации. Почему важна производная? Потому что мы можем вес как увеличить, так и уменьшить. И чтобы сместиться в правильную сторону, нам нужно учесть производную.
Значит, раньше у нас была ошибка только на выходе. Теперь мы посчитали ошибку для первого слоя нашей нейросети. Теперь вопрос в том, как мы посчитаем ошибку для следующего слоя? Мы применяем тот же самый метод, пока не дойдем до самых первых весов. Таким образом, у нас ошибка как бы растекается по нашей нейросети и веса корректируются. Этот алгоритм получил название метода обратного распространения ошибки, потому что ошибка распространяется как бы от выхода к началу. И это очень мощный алгоритм (метод обратного распространения ошибки.- “Ъ”), потому что его придумали в начале 1970-х годов, и с тех пор все нейросети только этим алгоритмом тренируются. То есть все, что я буду сегодня рассказывать, натренировано алгоритмом, который принципиально работает по такому же принципу. Как я говорил, нейросети возникли еще в 1950-х годах, но для того, чтобы изобрести этот алгоритм, потребовалось двадцать лет. А после понадобилось еще двадцать-тридцать лет, чтобы возникло глубокое обучение. Там были собственные проблемы. Все те архитектуры, которые вы сегодня увидите, очень сложные. Они все натренированы алгоритмом обратного распространения ошибки. Самые сложные пытаются даже смоделировать машину Тьюринга, то есть сделать универсальный компьютер на нейросетях.
Почему нейросети вдруг стали настолько эффективны? Оказалось, что нейросетевые методы проигрывают классическим методам статистики, если данных мало. Если у вас есть десять картинок Незнайки и десять картинок кошки, то нейросети применять бессмысленно. Вы не сможете их натренировать и не сможете получить хорошее качество работы. Однако если у вас есть 10 тыс. Незнаек и 10 тыс. кошек, то здесь нейросети побьют любые алгоритмы, построенные на классических методах. Пятнадцать лет назад ни у кого не было достаточных вычислительных мощностей, чтобы строить и обрабатывать большие нейронные сети, да и больших объемов данных, на которых можно было бы обучаться, не было. Только поэтому никто не знал, что если сделать сеть поглубже и дать побольше данных, то можно получить такие впечатляющие результаты. Но появились графические ускорители для расчета игр в реальном времени, и оказалось, что их можно использовать для того, чтобы тренировать нейронные сети, потому что там в матрице перемножаются такие операции, которые на этих ускорителях очень хорошо распараллеливаются. И это привело к той революции нейронных сетей, про которую мы сейчас узнаем.
Существуют три основных направления в области глубокого обучения. Это направление, связанное с компьютерным зрением, где нейронные сети пытаются что-то увидеть во внешнем мире, направление, связанное с предсказанием последовательности, где нейросети пытаются понять, что происходит в окружающем мире, и так называемое обучение с подкреплением, где нейросети учатся чем-то управлять. Рассмотрим каждое из них.
В компьютерном зрении основным алгоритмом является так называемая сверточная нейросеть. Что представляет собой эта модификация нейросети? У вас есть две функции - f и g. Функция свертки этих двух функций заключается в том, что вы эти две функции просто сдвигаете относительно друг друга на определенную величину, перемножаете все значения и складываете их. Соответственно, если у вас есть ступенька и треугольник и они друг с другом не совпадают, то функция свертки будет равна нулю, потому что эти функции вне этой области равны нулю. Но есть некоторая область значений сдвигов, для которой у вас, когда они максимально совпадают, значение функции свертки будет максимальным. Отсюда понятно, как мы можем это использовать для анализа изображений. У вас есть картинка и есть некоторый паттерн, который вы хотите найти в этой картинке, то есть у вас есть, например, Незнайка или кошка и вы хотите найти, где у этой кошки глаз. Вы можете закодировать некоторый паттерн яркости, который похож на глаз, и потом этим паттерном просканировать все изображение. Фактически вы вычисляете свертку изображения с паттерном глаза. Соответственно, в том участке изображения, который будет наиболее похожим на тот паттерн, который вы ищете, у вас функция свертки будет максимальной. Там вы сможете построить карту изображения, на которой максимальное значение будет в тех областях, в которых как раз ваш паттерн и находится.
А теперь представьте, что вы хотите распознавать сложные изображения, которые состоят из многих признаков. Что вы делаете? Фактически это у вас как один нейрон. У нейрона есть девять входов, выход, веса. Ваш паттерн - это веса. Вход - это фактически ваше значение яркостей. Вы перемножаете веса на вход этого нейрона, складываете их и получаете некое значение. Это значение - выход вашего нейрона, то значение свертки, которое вы хотите получить. Соответственно, вы делаете много нейронов, случайно задаете им веса. То есть изначально, когда вы решаете задачу, вы не знаете, какие признаки позволят вам отличить кошку от Незнайки. В принципе вы знаете, что у кошки есть полоски, а у Незнайки - шляпа. Для какой-то другой задачи будут другие признаки. И вы хотите универсальный алгоритм, который будет находить те признаки, которые будут наиболее информативны для разделения двух категорий. Соответственно, вы строите такую сеть, в которой на вход подается задача распознавания, соответственно, у вас есть некоторое число входных сверточных нейронов. Каждый из них строит свою карту признаков. Затем происходит определенная операция сжатия этих карт признаков, а потом эти карты признаков подаются на другие сверточные нейроны, и они ищут признаки уже в этих картах признаков. И так мы эту операцию можем проводить несколько раз, постепенно выискивая признаки все более и более высоко уровня абстракции. А затем эти карты признаков подаются на нашу полносвязную сеть прямого распространения, в которой наш сигнал передается от входных к выходным нейронам, и в конце у нас стоит классификатор. Вот так, очень просто, устроены сверточные нейронные сети.
Что сегодня мы можем сделать при помощи самых интересных сверточных сетей? Во-первых, мы можем локализовать объекты. То есть нейросеть может определить, что находится в некоторой рамке. Во-вторых, можем разметить и сегментировать изображение. В-третьих, алгоритм может определить пол и возраст человека. То есть если у нас было много примеров людей разного пола и возраста и мы натренировали нашу нейросеть предсказывать возраст и пол людей, то она нам будет предсказывать возраст и пол людей по изображению. В-четвертых, она может определять эмоции человека, если у нас был размеченный набор обучающих данных, в котором мы знали, с какими эмоциями присутствовал человек. Вот такие классные приложения. Сейчас любой разработчик может подписаться на сервис «Облачный Microsoft», загрузить свои фотки, и сервис через две минуты выдаст вам все эмоции или возраст с полом. То есть это, фактически, технологии, которые сейчас любой человек может использовать в своих продуктах.
Можно делать другие интересные вещи. Наверняка вы все слышали о приложении Prisma. Что мы можем сделать с его помощью? Мы можем перенести стиль одного изображения на содержание другого. Это как раз позволяют сделать наши сверточные слои. Мы можем найти, как признаки скоррелированы друг с другом в одном изображении, а потом перенести эту корреляцию признаков на содержание другого изображения. Ну и есть примеры того, как мы можем Храм Василия Блаженного раскрасить под хохлому. Такой быстрый инструмент, при помощи которого дизайнеры, например, могут совмещать какие-то две разные идеи. Мы можем научить нейросеть читать по губам. Если у нас есть субтитры и видео с человеком, который говорит, то мы можем отобразить его речь в тексте и построить такую нейросеть, которая предсказывает текст. Если у вас есть видео без звука, но видно, как человек говорит, то вы можете восстановить текст автоматически.
Но, оказывается, можно сделать и более сумасшедшие вещи. Есть такой подход - генеративные соревновательные сети (generative adversarial network - GAN). Это такой тип нейросетей, который использует автоэнкодеры - когда мы сначала кодируем изображение, а потом его восстанавливаем. Мы можем их использовать для того, чтобы натренировать хитрые генераторы изображений. То есть мы сначала преобразуем изображение в некое скрытое представление из нашего внутреннего скрытого слоя - это называется энкодер-часть, а потом подаем наше скрытое представление на вход декодера, и оно выдает картинку. Мы можем взять три картинки с изображением лица мужчины в очках, для каждого из них у нас будет скрытое изображение внутри нашей нейросети. Это будет некий вектор в некоем пространстве изображений. Теперь мы сложим эти три вектора и усредним. Получится некое усредненное изображение мужчины в очках. Потом мы возьмем три изображения мужчин без очков, подадим их скрытые представления на вход нашей нейросети, усредним векторы - и получим усредненное изображение мужчины без очков. То же самое мы можем проделать для женщины без очков. Итого у нас получилось три вектора. Теперь мы можем взять вектор мужчины в очках, вычесть из него вектор мужчины без очков и прибавить вектор женщины без очков. Тот вектор, который у нас получился, мы подадим на декодер, и наша сеть сама сгенерирует изображение женщины в очках, хотя она этой картинки никогда не видела. Могут быть варианты - очки с разной яркостью, женщина слегка не та, что мы прибавляли, но в целом эффект может получаться очень интересный.
Буквально пару недель назад на конференции NIPS компания InVideo представляла развитие этой технологии, в рамках которой вы можете на основе взятых черт знаменитостей сгенерировать усредненное изображение этих знаменитостей и даже синтезировать видео с этими людьми. Фактически вы можете создавать некие синтетические личности, которые будут присутствовать в ваших сериалах или фильмах. Так вы можете сэкономить кучу денег, потому что вам не нужно будет платить настоящим актерам.
Следующая задача - рекуррентные нейронные сети. Они могут предсказывать последовательности. Чтобы предсказать последовательность, нам нужно знать некую историю. В стандартных нейросетях у нас есть Х на входе, есть некоторый слой нашей нейросети, есть выход, и информация распространяется все время прямо. Если же мы возьмем другой отсчет времени, то наша нейросеть забудет о том, что она знала в предыдущем отсчете. Но для того, чтобы иметь возможность предсказывать, нам как раз нужно, чтобы нейросеть помнила о многих отсчетах времени. Как это сделать? Обычно это решается так: мы берем выход нашей нейросети за предыдущий момент времени и подаем эти значения ей же на вход, на слой нейросети. Что-то пришло в момент времени T, но пришло не только то, что передал ей предыдущий момент Т, но и то, что она сама выдавала в момент времени Т-1. Таким образом, мы сразу подаем параллельно два вектора. И на основании этого вычисляем значение выхода для момента времени Т. Получается, что нейросеть может сама себе передавать то, что она «думала» в предыдущий момент времени. Это позволяет сохранить информацию о предыдущих входах. Такой тип нейросетей и называется рекуррентным, потому что они имеют рекуррентные связи. Если мы подойдем в лоб к решению этой задачи, то рекуррентные нейросети работают не очень хорошо, потому что когда мы разворачиваем эту обратную петлю, то фактически наращиваем слои нашей нейронной сети. От момента времени 0 наша нейросеть будет погружаться все глубже и глубже - в момент времени 100 нейросеть наша тоже будет глубиной 100. Поскольку ошибка в обратную сторону распространяется, она постоянно растекается по нашей сети и затухает. Поэтому наша нейросеть очень плохо учится, так как каждый раз происходит умножение на некоторые коэффициенты и наши ошибки затухают.
Чтобы избавиться от этого затухания градиентов, в 1997 году исследователь Юрген Шмидхубер предложил заменить один нейрон на подсеть из пяти нейронов. То есть теперь слой нейросети состоит из «юнитов». Смоделируем ячейку памяти. У нас есть некоторые значения, которые хранятся в этой ячейке. Есть нейроны, которые могут управлять тем, что мы можем что-то в эту ячейку памяти записать, что-то из нее считать и вывести наружу. При этом управление ячейкой осуществляется индивидуально своим набором нейронов. Веса этих нейронов тоже обучаются - и в этом вся красота полученной архитектуры. Когда мы из этих ячеек построим большую нейросеть, они все будут обучаться с помощью алгоритма обратного распространения ошибки. То есть алгоритм у нас остается тот же самый, даже несмотря на то, что сеть у нас значительно усложнилась.
Это позволило, например, создать систему машинного перевода. Буквально год назад Google заменил свою старую систему машинного перевода на нейросетевую - значительно лучшего качества. По сравнению со старой версией машинного перевода Google 2015 года человеческий перевод получал гораздо больше оценок. Но по сравнению с новым нейросетевым алгоритмом Google, который используется сегодня, оценки человеческого перевода сопоставимы. На самом деле переводом вы пользуетесь каждый день - когда забиваете что-то в поиске, то второй и третий по значимости сигнал по тому, какой ресурс вы получите в выдаче на первой странице, тоже определяется нейросетями. Представители Google все время показывают график, в котором с каждым годом все больше и больше внутренних проектов используют нейросети и глубокое обучение. Если в 2012 году это были один-два проекта, то сегодня - около 5 тыс. Фактически нейросети - это та технология, которой вы пользуетесь каждый день, хотя, быть может, даже этого не подозреваете. Некоторые люди, которые этим занимаются, провозгласили, что нейросети и искусственный интеллект - это новое электричество. В том смысле, что это та технология, которой мы пользуемся, не замечая, но она плотно вошла в нашу жизнь.
Какого же эффекта мы можем достичь с помощью этих рекуррентных нейросетей? Я покажу вам результаты, которые поразили меня до глубины души. Если бы мне кто-то сказал за месяц до этого, что такое возможно, а это было летом 2015 года, я бы ответил, мол, ребята, я занимаюсь нейронными сетями десять лет, не надо мне рассказывать сказки. Но когда мы сами взяли нейросеть, провели ее обучение и увидели результат, который она выдает, то убедились, что это на самом деле так. Мы решали задачу моделирования языка. Формально это задача предсказания следующего символа. Например, у нас есть куча текстов Достоевского. Мы подаем на вход нашей нейросети 100 символов (букв, включая пробелы и знаки препинания) из произведений Достоевского, и ее задача - предсказать следующий символ. Этот символ мы можем снова подать на вход и предсказать следующий - и так далее. Но нам не хотелось экспериментировать на Достоевском, поэтому мы взяли субтитры к сериалу - примерно 10 млн слов из «Хроник вампиров» и еще чего-то. На этом материале сеть училась предсказывать следующие символы.
Итак, задача: есть 100 символов, нужно предсказать 101-й. Мы выложили в интернет интерфейс, где можно было забить какую-то начальную фразу, а нейросеть пыталась ее продолжить. Я отобрал наиболее интересные результаты. Человек пишет: «Ты глупый». То есть на вход нейросети подаются все эти буквы, пробел между «ы» и «г», а также перевод строки. И она предсказывает следующий символ: «К» большое. Мы подаем эту «К» ей на вход, она предсказывает следующий символ «а», подаем на вход «а» и т. д. - в результате получаем сгенерированную фразу: «Как насчет “привет”». Когда мы анализирует этот ответ, он выглядит абсолютно логично. Причем у него есть особенности: почему нейросеть сказала про привет? Если это начало диалога, то логично, что с фразы «ты глупый» не начинают. Поэтому нейросеть говорит: «Как насчет “привет”», причем слово «привет» закавычивает, давая понять, что это слово относится не к ней самой. Так что пусть у нашей нейросети и нет научной степени по филологии, но уж знания русского языка у нее глубокие.
Другой пример. Я попытался задать более сложный контекст, чтобы нейросети было непросто ответить. Вопрос: «Какой чудный вечер. Не правда ли?» Это довольно длинная последовательность символов, два предложения, много пробелов, знак вопроса. Вот ее ответ: «Ты действительно думаешь, что я буду помнить об этом?» Здесь ничего про вечер не сказано, ответ вопросом на вопрос. Но если мы попытаемся проинтерпретировать, то это вполне осмысленно. То есть если вечер чудесный, то подразумевается, что тот, кому про это сказали, захочет это запомнить. Отсюда такой ответ нейросети. И отдельно обратите внимание, что она (нейросеть.- “Ъ”) еще и знаки препинания правильно расставляет, и ошибок в словах не делает. И это при том, что мы в нее не закладывали правил русского языка, словаря слов, никаких грамматических основ - мы дали нейросети только последовательность символов. Мне кажется, что в таких условиях выдача подобных ответов - просто поразительный феномен. Я до сих пор удивляюсь: как она может это генерировать?
Еще один пример. Здесь вообще получился очень жизненный диалог. Человек: «Ты дура». Машина: «Так почему тебе не все равно?» Человек: «Потому что мне с тобой жить!» Машина: «Ты совсем не такой!» Человек: «Ты обиделась?» Машина: «Угу». Покажу еще пример ее работы. Человек: «Забавно, но ты всего лишь программа и никогда не сможешь мыслить». Машина: «Конечно, дело в том, что сейчас не лучшее время». Все логично, да? Но это ваша интерпретация, нам не известно, что на самом деле нейросеть имела в виду, это же все из сериалов.
А теперь - про разнообразие, которое порождала нейросеть. В принципе эта нейросеть является вероятностной моделью текста, она выдает вероятность следующего символа, но не точно, какой будет следующий символ. И мы можем пропорционально этой вероятности выбирать. Таким образом, мы можем генерировать разные последовательности. В одном случае на один и тот же вход мы выберем одну букву, в другом случае - другую. Мы подаем на вход предложение: «Алиса теперь счастлива». И просим нейросеть продолжить. Предсказать, как бы эта последовательность продолжалась. Везде продолжение начинается со слова «она». То есть нейросеть как бы улавливает, что здесь было про Алису и «счастлива», пол того субъекта, про который идет речь. В некоторых ответах есть нечто, что коррелирует с тем, что она счастлива. Например: «Она выглядит прекрасно». Или она была на концерте, поэтому она счастлива. Или она великолепна или влюблена, поэтому она счастлива. Или вот: «Она в опасности». Видимо, счастливые люди с большей вероятностью попадают в опасные ситуации, чем несчастливые. Можно сделать такой вывод. Или например: «Алиса попала в беду». Здесь мы видим, что тональность уже сменилась: «А она не знает кто ты», или «А она изменила свою жизнь», или «Она не собирается никого убивать». Раз она попала в беду, в ответах появляется что-то уже тревожное. А откуда появились эти нотки, мы не знаем. То есть нейросеть зачем-то вставила эти нотки. Из субтитров. Там были знаки ноток.
Но, видимо, в субтитрах все-таки больше про женщин, потому что на женские затравки она отвечает более осмысленно, а на мужские, наверное, не хватает статистики. «Джон теперь счастлив». - «Да, на дворе 800 фунтов на каждом месте», «Преступление в тысячу тысяч градусов по матче», «В самом деле собирался позволить себе просто бросить все на свои места». То есть осмысленность ответов сильно пострадала, хотя предложения изначально схожие. А вот «Джон попал в беду» - совсем тяжело: «Свиньи собираются в Старлинк-сити», «И когда он вернулся, я выбросил его в офис», «Он был не таким как был в прошлом году», «Сверхъестественное, ваша честь, это был не мы».
Я не знаю, насколько это вас впечатлило, меня это впечатлило очень сильно. Мой прогноз был бы такой, что, возможно, нейросеть сможет выучить некоторые слова из пяти букв и воспроизводить их в некотором случайном порядке. Но под прогнозом, что она сможет без ошибок генерировать такие длинные фразы, которые можно осмысленно интерпретировать, я бы, честно говоря, никогда не подписался.
Давайте я еще быстренько расскажу о том, о чем все волнуются в последнее время. Нейросетевое обучение с подкреплением. Это такой подход, который необходим для того, чтобы выучить некоторые действия у агента. Каждые действия агента как-то при этом меняют среду. В предыдущих задачах мы прогнозировали, но не влияли на саму задачу. Мы не влияли никак на изображения, которые классифицируем, не влияли никак на последовательность, которую мы генерируем. А здесь наша задача ставится так: мы хотим повлиять на тот вход, который у нас есть, чтобы привести в то целевое состояние, которое нам необходимо. Агент - это некоторый субъект, который может воздействовать на окружающую среду. Мы не знаем, как решать эту задачу по обучению агента. Но мы знаем, что такое хорошо и что такое плохо. Поэтому мы можем в те моменты, когда агент достигает той цели, которую мы перед ним поставили, давать ему некую величину, которую мы называем наградой или подкреплением. Таким образом, нам необходимо получить алгоритм, который будет по последовательности и по наградам выучивать такие действия, которые в данной ситуации будут максимизировать награду.
В 2016 году в журнале Nature вышла статья, где был описан достаточно универсальный алгоритм, который научили играть в игры Atari. И он попал на обложку журнала Nature. Если вы знаете, журнал Nature - это один из наиболее авторитетных и престижных еженедельников в мире науки, где публикуются действительно научные статьи. Если ты напечатал статью в Nature, то твой авторитет среди ученых очень сильно возрастает. Бывают, конечно, исключения, но в основном там действительно публикуются очень важные с точки зрения науки работы. Как ставится задача? У нас есть 49 игр Atari, мы подаем на вход нашей нейросети картинки из этих игр, но никак не объясняем правила. Мы будем одну и ту же нейросеть учить на разных играх и хотим, чтобы она на всех играх училась хорошо. Но нейросеть одна, и под конкретную игру она подстраивается только в процессе обучения. Заранее мы ничего не закладываем.
Соответственно, у нас есть картинки, которые попадают на вход нашей нейросети, но вы все знаете, что такое сверточные сети - я рассказывал полчаса назад. Сверточные нейросети преобразуют картинки, выделяют признаки, и на выходе нейросети она выдает действие, которое управляет джойстиком. Соответственно, команды от джойстика передаются в симулятор игры, и он управляет поведением игры. Когда вы набираете очки, ваш агент получает подкрепление, и задача агента - увеличить эти очки. То есть здесь мы не говорим ему напрямую, какие действия выбирать, а просто в тот момент, когда он увеличил очки, говорим, что это хорошо. И задача - обучить этот алгоритм. Например, нейросеть управляет подводной лодкой. Задача: рыб - уничтожать, водолазов - подбирать и время от времени, когда кислород заканчивается, всплывать и заряжаться кислородом. Нейросети это удается не всегда, иногда она погибает. Но оказывается, что этот результат нашел не только научное признание и попал на обложку журнала Nature, а был получен некоторым стартапом, и за пару месяцев до того, как это было опубликовано, этот стартап купила компания Google. При этом из результатов у этого стартапа были только те, которые они публиковали в журнале Nature. Как вы думаете, за сколько компания Google купила этот стартап? За 600 миллионов.
Следующий вопрос. Что связывает Гарри Каспарова и Ли Седоль, чемпиона по го (игра.- “Ъ”)? Правильно. Их обоих победил искусственный интеллект. В 1997 году DeepBlue обыграл Каспарова, а чемпиона го обыграли в прошлом году. Почему так? До последнего времени считалось, что го - очень сложная игра. Это связано с количеством вариантов, которые нужно перебрать, чтобы рассчитать все возможные исходы игры, и описывается так называемым коэффициентом ветвления. То есть во сколько возможных состояний игры мы можем перейти из текущего состояния игры, совершая разрешенные в игре действия. Для шахмат средний коэффициент ветвления - около 35. А в го этот коэффициент ветвления - 250. Соответственно, вы понимаете, что когда мы идем вглубь, то каждый раз мы умножаем на это число. И понятно, что для го мы очень быстро получаем такое количество вариантов, которое превышает число частиц в наблюдаемой вселенной, и перебрать их не представляется возможным. Нужен какой-то другой вариант решения этой задачи. Если в шахматах мы можем в лоб рассчитать варианты для очень большого числа позиций и тупо знать те ходы, которые нужно сделать, чтобы выиграть или не проиграть, то в го это гораздо сложнее. Многие люди говорили, чтобы распознавать все ситуации, нужна интуиция.
Тот же самый стартап, который купили за 600 миллионов, через год снова появился на обложке журнала Nature. Теперь он предложил алгоритм, который, глядя на доску, мог выдавать оценку того, насколько эта позиция хороша, то есть достаточно быстро предсказывать. Вы можете скомбинировать это предсказание с алгоритмом поиска по дереву и при помощи нейросети оценивать позиции и раскрывать только те, которые являются наиболее выигрышными. Таким образом, вы делаете не полный перебор, а только под дерево, которое является наиболее перспективным в данный момент. Этот алгоритм - версия AlphaGo (в статья была опубликована версия AlphaGo Fan) - и обыграл Ли Седоля в Го. Тогда программы в го играли на уровне хорошего любителя, но не профессионала. Чтобы обучить эту версию, нужно было 176 графических процессоров на распределенном кластере. И она выиграла у чемпиона Европы со счетом 5:0.
Затем появилась адаптированная версия программы - AlphaGoLee. Она использовала 48 Tensor Processing Unit - это типа TPU, но специально адаптированных под нейросети. У Ли Седоля она выиграла со счетом 4:1. Потом была AlphaGoMaster на 4 TPU, которая выигрывала у профессиональных игроков со счетом 60:0. Буквально месяц назад появилась программа AlphaGoZero, которая на 4 TPU на одном компьютере (уже не на кластере) обыграла со счетом 100:0 ту версию программы, которая обыграла Ли Седоля, и со счетом 89:11 - версию AlphaGoMaster. Следующую версию опубликовали несколько дней назад - AlphaZero. Она, опять же, на четырех TPU со счетом 60:40 сыграла против AlphaGoZero. Первая версия программы AlphaGoLee сначала тренировалась на реальных играх. То есть была взята база данных игр, и на ней программа училась играть, как человек. А вот программы AlphaGoZero и AlphaZero - почему Zero? Потому что они вообще не использовали никакой информации от человека. Как они училась? Просто играли сами с собой и обучались на своих играх. И вот так хорошо обучились.
Теперь вопрос. Зачем компания Google купила эту штуку? Она взяла этот алгоритм, который использовался для игр, и приложили к задаче управления охлаждением дата-центра. Теперь в момент, когда включается нейросетевое управление, потребление падает, когда выключается - возвращается к старому уровню. В среднем экономия около 40%. Google поддерживает огромное количество дата-центров, чтобы обеспечить качество сервиса, и для них экономить по 40% на электроэнергии, а для дата-центров электроэнергия - вообще основная затратная статья, это очень существенно. Не знаю, окупилось ли, но, по крайней мере, существенную часть, возможно, возместило.
За свою историю искусственный интеллект переживал взлеты и падения, и сегодня мы находимся на самой вершине нового ажиотажа вокруг искусственного интеллекта , где все считают, что искусственный интеллект - «новое электричество» и так далее. Возможно, скоро этот ажиотаж спадет, но сейчас самый пик. Почему здесь в зале так много людей, большинство из которых не знают, что такое глубокое обучение, и все равно пришли. Видимо, тема добирается из других сфер жизни и привлекает сюда людей. Пик интереса связан с тем, что давно известные нейросетевые алгоритмы за счет больших данных и больших вычислительных возможностей стали решать те задачи, которые раньше не могли быть решены, и давать очень интересные результаты, которые могут быть внедрены в очень многих областях экономики.
Соответственно, что делаем мы в этой области? В нашей лаборатории мы реализуем проект, поддержанный Национальной технологической инициативой - это инициатива нашего президента, связанная с попыткой переставить какие-то части нашей экономики с сырьевых рельсов на высокотехнологичные. Инициатива связана, с одной стороны, с поддержкой инновационных бизнесов, а с другой - с инфраструктурой для этих инновационных бизнесов. Соответственно, в рамках этой национальной технологической инициативы Физтех при софинансировании Сбербанка выполняет проект. И цели проекта - это разработка алгоритмов глубокого машинного обучения и машинного интеллекта в виде некоторой технологической платформы для автоматизации ведения целенаправленного диалога с пользователем.
Сегодня у нас возникает целая область экономики, связанная с текстовой коммуникацией. Люди пользуются мобильными устройствами, и число пользователей мессенджеров на мобильных платформах уже превысило число пользователей соцсетей. Это значит, что огромное количество коммуникаций люди осуществляют в текстовом формате. Но при этом нет хороших инструментов для компаний, чтобы общаться в этом мире с пользователями. Есть большой запрос на решения, когда компании могли бы достучаться до вас, как-то вам помочь или решить какую-то вашу проблему через чат. С другой стороны, те решения на создание диалоговых систем, которые до последнего времени существовали, не очень эффективны, потому что они основаны на некоторых закодированных сценариях, заданных программистом, и эти сценарии, как оказалось, не очень хорошо масштабируются и не могут описать все многообразие нашей разговорной жизни. Разные люди по-разному выражают свои мысли, бывают разные ситуации, и все это очень сложно воспринять и заранее предусмотреть. Но, как мы видели, нейросети очень хорошо справляются с такой неопределенностью. Они могут генерировать ответы, похожие на ответы человека. Они могут делать машинный перевод. И поэтому есть надежда, что мы сможем использовать нейросетевые технологии для того, чтобы решить хотя бы часть проблем в создании разговорных интерфейсов.
Таким образом, цель этого проекта - как раз создать такую открытую платформу, которая могла бы быть использована компаниями для создания продуктов в этой области. То есть мы создаем технологию, отдаем ее компаниям и говорим: «Мы вас будем поддерживать, мы будем вам помогать эту технологию внедрять, а вы, пожалуйста, делайте свои бизнесы и вносите свой вклад в экономику». Каковы стейкхолдеры нашего проекта? С точки зрения NTI, это компании на высокотехнологичных рынках. Например, Сбербанк, который хочет, имея эту технологию в качестве основы, создать решения для автоматизации каких-то сервисов, например, call-центров или служб поддержки. Это Физтех, которому интересно развивать внутри себя компетенцию по искусственному интеллекту. Это исследователи и разработчики, которым нужны инструменты для того, чтобы быстро создавать таких интеллектуальных диалоговых агентов.
Этот проект мы начали летом этого года и назвали его iPavlov в честь Ивана Петровича Павлова, знаменитого русского нейрофизиолога, который занимался исследованием условных рефлексов. То есть мозгом. Соответственно, два основных результата нашей деятельности с точки зрения технологии - это открытая библиотека, которую мы назвали DeepPavlov, и это как раз набор инструментов для создания диалоговых систем, а также набор сервисов Сбербанка, который они будут встраивать в свои продукты, например, каких-то финансовых помощников. У нас есть исследования, есть разработка нашей библиотеки, есть приложения этой библиотеки для каких-то конкретных бизнес-кейсов. Что мы хотим сделать? Мы хотим сделать набор некоторых нейросетевых блоков, из которых мы можем собрать разных агентов под разные задачи. Например, агентов, которые могут решать конкретные задачи типа бронирования билетов, или агентов, которые могут отвечать на вопросы по какой-то тематике, или агентов, которые могут просто поддерживать беседу. И потом эти агенты могут комбинироваться для каждой конкретной области, чтобы оптимально решать поставленную задачу. Это то, как мы планируем реализовывать архитектуру с точки зрения ее нейросетевого и исследовательского содержания. И, с одной стороны, наша библиотека состоит из компонентов для создания этих ботов. С другой стороны, у нас есть некоторый инструмент Bildert, при помощи которого мы можем собирать из этих ботов разговорных агентов, есть коннекторы, которые соединяют нас с мессенджерами, и есть данные, на которых мы тренируем. То есть это некоторый набор инструментов, при помощи которых можно разрабатывать и внедрять такие решения.
Наверное, на этом можно закончить. Спасибо всем.
Евгения Чернышева